We’ve discussed the intuitive idea of an mechanical or effective algorithm. When it’s an algorithm for answering a yes/no question, such as whether some value has a property/belongs to some set, we say we’re talking about the set being effectively decidable. When it’s an algorithm for answering a more general question, whose answer is the result of some function for specified arguments, we say we’re talking about the function being effectively calculable or computable.
One kind of formal model of effective algorithms is called Turing Machines, based on ideas Alan Turing proposed in 1936. (The name was coined by others. Some authors say “Post-Turing Machines” because some of these ideas were also suggested by Emil Post around the same time.) In the time since, these models have been construed in a variety of different ways — we can call them different flavors or variant ideas of what a Turing Machine’s capabilities are. As we’ll dicuss at the end, all the variants are translatable into each other.
We’ll start with a particular flavor or variant of Turing Machine, and talk about alternatives later. Our presentation will draw on ways that Turing’s initial proposals were refined by others later (especially Post and Minsky).
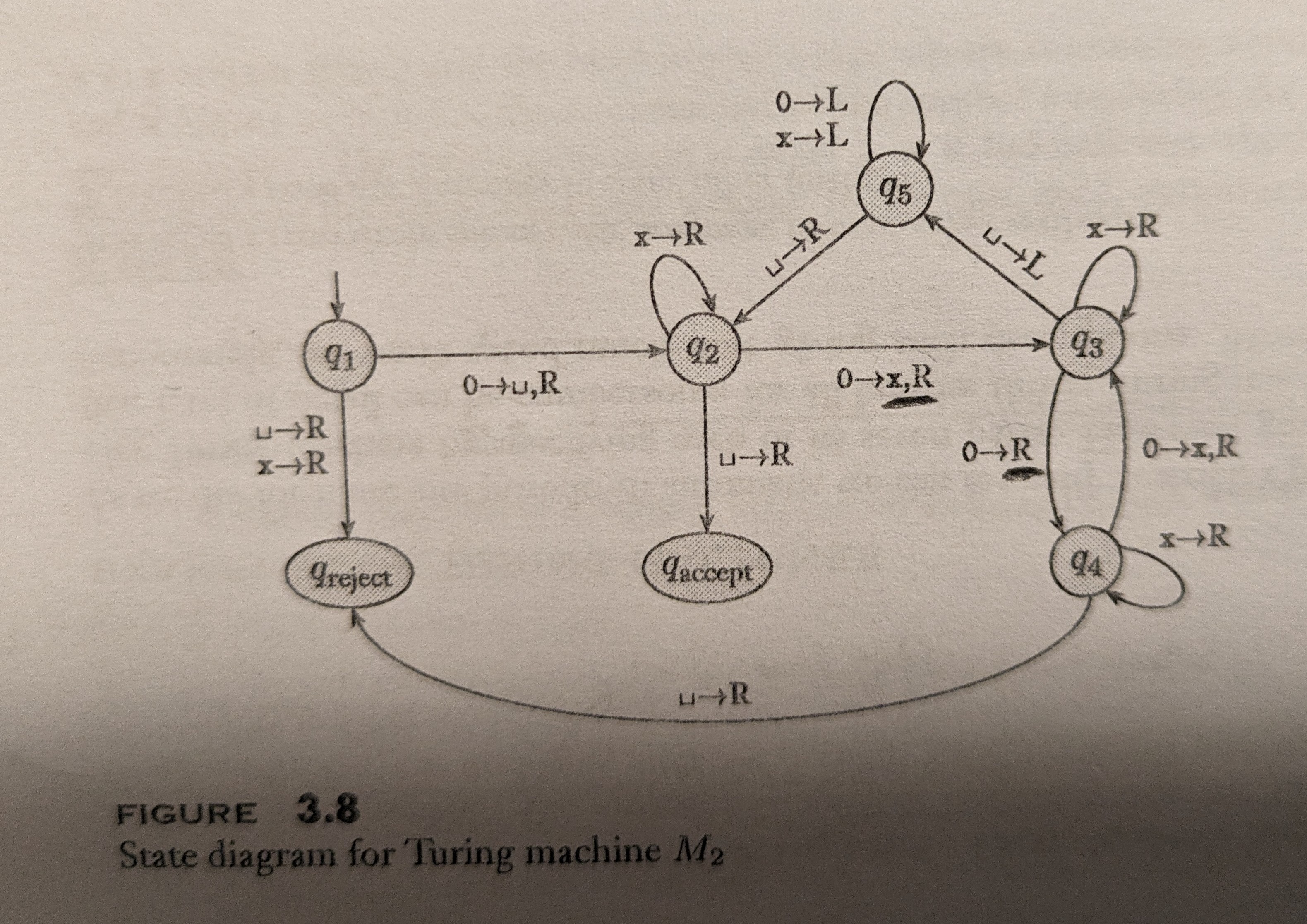
The variant you choose gives you the background rules. Against that background, a particular Turing Machine is understood to be a finite program or structure of instructions. You can think of it like a listing of source code, only we don’t assume that after executing each instruction we always proceed to the next instruction in the listing. Instead each instruction explicitly says what the next step should be. Instead of a list of instructions, then, it’s more natural to think of the program as being a kind of flowchart, like this:
Each Turing Machine also has a memory tape to receive any input arguments from, and also to use as scratch paper to save its intermediate results as it works, and sometimes to return its answers on. We’ll talk about this more below. At each step in the algorithm, the program can read a single square on its memory tape, which has some symbols from a specified alphabet on it. (What the possible alphabet is, is understood to be part of the program.) In the flowchart, notice that the arrow from node q2 to node q3 is labeled 0⟶x,R. What this means is that when the program’s execution is at node q2 in the flowchart, if the symbol then readable from the memory tape is 0, it should overwrite it with the symbol x and move the scanner/read-write head one square Right on the memory tape. (In the arrow from node q3 to node q4, there’s no designation of what to write to the tape; this is shorthand for saying “overwrite with the same symbol 0 that’s already there,” or in other words, “leave the current symbol alone.”)
It’s important to this formal model that any Turing Machine program has an unbounded amount of memory/scratch space to work with during its execution. We’ll assume the memory tape has a left edge but extends indefinitely to the right. The alphabet of symbols will include a special symbol called “blank” and written as ␣ (or sometimes b or 0, but not in our diagrams), which is what all of the as-yet unused memory squares start out containing. The alphabet will usually include at least one more symbol, and often many more (but only finitely many). Only trivial programs that take no input and make no meaningful use of their memory tape can get by with only the blank symbol.
Any effective algorithm has to complete after a finite number of steps, but there is no bound on how many steps it may take. After a finite number of steps, any Turing Machine program will only have been able to access a finite number of squares on its memory tape, but again there should be no bound or upper limit to how many it can eventually use.
Since our tape has a left edge, if the scanner/read-write head is located on the leftmost square, and some step of the program says it should move Left, it just stays where it is. There’s no error or feedback given to the program that you’ve hit the edge. Some programs do need to keep track of where the left edge of the tape is; and so they’ll use a strategy like writing a special symbol there and watching out for when that’s what they’re reading.
As I said, a given Turing Machine is identified with its flowchart, and this is a finite description that’s specified in advance and doesn’t change. One of the nodes in the flowchart is designated as the Starting node. Sometimes nodes in the flowchart are designated as Accepting or Rejecting or Halting nodes; we’ll talk about these below. As the program proceeds or executes, our position in the flowchart will change. And also what’s written on the memory tape, and the location of the scanner/read-write head on that tape will also change. But the flowchart itself is a fixed structure. The only things that change during the program’s execution are the three facts I just italicized. The combination of the three of these is sometimes called the “complete configuration or execution-state” of that stage of the program’s execution, or its “instantaneous description.”
If you really wanted to dynamically modify a program’s flowchart while it’s executing, you could get that effect by having your memory tape encode the description of another Turing Machine’s flowchart, and then your own flowchart would read those instructions (which could be modified, since they’re written on your tape) and calculate what the step-by-step behavior would be of the described Turing Machine program’s executing on some specified input. Any Turing Machine whose flowchart enables it to “host” or simulate in this way the execution of another Turing Machine, described on its tape, is called a Universal Turing Machine. These don’t have any special capabilities over other Turing Machines; they just have flowcharts designed to achieve this purpose. What input does the host feed its simulated Turing Machine? That would either be hard-wired into the host, or might be another argument the host reads from its memory tape.
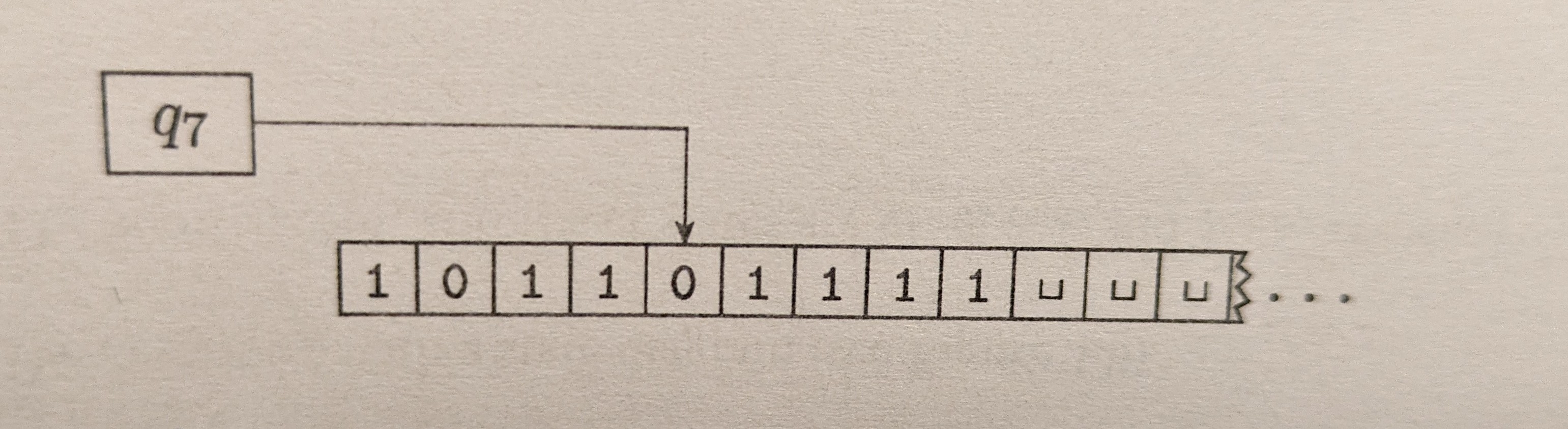
Here’s a picture of a Turing Machine’s memory tape during the execution of its program. The box labeled q7 and the arrow pointing to the square on the tape containing a 0 symbol mean that the program is currently executing node q7 in its flowchart, and that the scanner/read-write head is located at the designated square on the tape. Currently this program would be reading a 0 from its tape.
Since Turing Machines need to have access to potentially unbounded amounts of memory, they are abstract mathematical blueprints that can’t always be physically realized. Also, since a Turing Machine is identified with its flowchart, if you are able to physically implement a particular one, and you made two physical copies, these would count as implementing numerically one and the same “Turing Machine.” Not two Turing Machines with the same program. The Turing Machine is the program. So the label “Turing Machine” can be misleading; it makes it sound like we’re talking about a piece of hardware. But we’re not. We’re talking about a formal mathematical model of an algorithm.
That said, here is a photo of a physical device someone built to act like the scanner/read-write head and (finite portion of) the memory tape of some Turing Machine. Here instead of the scanner moving Left and Right over the tape, the tape is pulled in the appropriate direction under the scanner/read-write head.

Let’s talk about how a Turing Machine program receives input, and how it delivers its answers/results/output. If the program needs input arguments, these will be provided as strings of symbols at the leftmost edge of its memory tape; if there are multiple arguments they will be separated by blanks. The rest of the tape after any input arguments starts off containing blanks.
How the program is understood to deliver an answer/result/output varies. If the program is just meant to deliver a yes/no answer, this can be communicated by what node the execution “halts” on. Often one node is called Accept and another Reject; these names come from the idea that what the program is doing is deciding whether a string supplied as input belongs to a given language (set of strings), where the language in question is hard-wired into the program. The answer Accept means “yes, this input does belong to the language/set of strings I’m designed to recognize.” The answer Reject means “no, it does not.” These special Accept and Reject nodes in the flowchart won’t have arrows leading out from them because when the program reaches them, it always halts its execution.
Sometimes instead of an explicit Reject node, theorists instead let this be specified implicitly, saying that if the program is ever executing a node and reads a symbol from the tape where there’s no flowchart arrow saying what to do for that symbol, that counts as Rejecting.
Understood in this way, the program’s entire answer just depends on where (on what node) in its flowchart it halts; the contents of its memory tape aren’t part of the delivered answer. The tape is just for feeding the program its input and for it to use as scratch space.
But what if the program is instead meant to deliver a more complex answer? For example, if we ask it to multiply the arguments "12" and "20", we want more than a yes/no answer. In such cases, we’ll want the answer to be supplied on the memory tape. Perhaps in the leftmost spaces of the memory tape (terminated by a blank), or alternatively we could let the answer be anywhere on the tape but understand that the scanner head will be positioned on the leftmost square of what’s supposed to be the answer. In these cases, usually there’s only one node where the flowchart halts, and it’s called Halt instead of Accept. (It may be specified implicitly, as described above for the Rejecting node.)
Or we could have more complex answers, where the program sometimes halts on an Accept node, and the answer should be read from its tape, but the program may also halt on a Reject node, which we understand as meaning something like the undefined results in our dissect-definitions.
For different theoretical purposes, different of these output conventions will be understood.
It’s easy to design a Turing Machine program that infinitely loops and never Halts. These programs are understood to be implicitly undefined for the arguments that made them behave that way.
Sometimes you can inspect a flowchart and just see or reason that the program will infinitely loop for certain arguments (or even all arguments!). But other times it’s more difficult to ascertain. An interesting question is whether we can devise an algorithm that would effectively compute this for us. That is, we would give it a description of a Turing Machine, and some arguments, and ask whether that Turing Machine program would ever Halt when given that argument (or those arguments) as input. Of course, we could try simulating the executing of the program on that input; if the simulation ever halts we could then say “yes, it Halts.” But if it’s been running a long time, we might not be able to tell whether it’ll still stop eventually, it just hasn’t gotten there yet; or whether the simulation would keep going forever. So that strategy won’t be effective: it won’t always give us a correct yes/no answer. But maybe there’s some other way to do this, by analyzing the described flowchart in a clever way. Do you think there might be a way to do it?
We’ve been talking about one variant or set of background rules for how Turing Machines work. There are many alternatives.
As it turns out, all these variants are translatable into each other, so there is no difference in terms of what questions/problems they can effectively answer. So we’ll say the different variant models are “computationally equivalent.” But some of the variants might deliver answers to certain problems in fewer steps, or might have smaller flowcharts, or might be easier for theorists to reason about in certain ways.
We said that the program needs to be able to read/write a blank symbol and (except in trivial cases) one more symbol to its memory tape. Expanding the alphabet of symbols a program is allowed to use (so long as it remains finite) doesn’t make a difference to what questions a Turing Machine can be programmed to effectively answer. So the variants with different alphabets are computationally equivalent.
Neither does letting the tape be infinite in both directions, rather than just one, make a difference to what questions a Turing Machine can be programmed to effectively answer. Nor does letting the read-write heads move an arbitrary number of squares left or right in a single step, rather than just one.
Neither does letting it have multiple read-write heads on the tape.
Neither does letting it have access to more than one (but a finite number of) tapes. Nor to a two-dimensional scractch space, instead of a one-dimensional tape. Nor to scratch spaces of higher dimensions.
Neither does letting the program be “nondeterministic,” in the way we described earlier.
Turing Machines can also be more restricted in some ways than the variant we described above, without affecting what questions/problems they can effectively answer.
The program may be limited to only being able to write to its tape, or move its read-write head, but not both in a single step.
The program may be limited to only being able to write onto blank squares, and never erasing or overwriting other symbols.
The program may be limited to having a one-way infinite tape, but where it can no longer move a single square Left. It only has the option to move a single square Right, or to “rewind” all the way to the left edge of the tape.
One variant idea is worth special mention. This can be thought of as having a one-way infinite tape, but instead of moving a read-write head left and right over the tape, we just specify a square we want to immediately read from or write to by its address. Also, we allow each square to contain any ℕ, so our alphabet is countably infinite. We let 0 play the role of a blank symbol. These kinds of machines are still computationally equivalent to the other Turing Machine variants we described. But they’re different enough that we no longer talk about them as “Turing Machines.” Instead these are called register machines. You may come across names like “abacus machine,” or “counter machine,” or “RAM”; these are labels for different flavors or variants of register machine.