There are a variety of “collections” that a mathematician or logician might work with. What are sometimes called strings or sequences or lists pay attention to the order of their elements; they also pay attention to the multiplicity of their elements. The string "a" is different from the string "aa". Other collections make other choices. Sets, for example, don’t pay attention to either the order or the multiplicity of their elements. The set {"a", "a", "b"} is the same as the set {"b", "a"}. We will be working with sets a lot this term.
Another collection, less often discussed, is a multiset. This pays attention to the multiplicity of its elements but not their order. So a multiset containing the elements "a", "a", and "b" will be the same as a multiset containing the elements "a", "b", and "a", but different from a multiset containing only "b" and "a" (once).
Graphs and trees are collections with more complex structures.
I’ll try to stick to the convention of naming sets with capital greek letters, like Δ and Γ. But I may sometimes slip; and there is no universal practice. (And sometimes ☺ I will use capital Greek letters like Α, Β, …) As a general convention, though, you should try to use capital letters of some sort to refer to sets (and expect others to be doing so too). Sometimes people use capital letters for other roles, too.
Sometimes these notes will be composed in the first-person singular, other times in the first-person plural. Understand them in every case as being offered by Matt and Jim jointly --- though it may happen that one or the other of us had a larger role in writing a given passage, and we may not always fully agree about all details.
As we said, sets are collections that may have elements or members. Their members may, but need not, also be sets. When the members aren’t sets, they’re called urelements or individuals or atoms. When d is a member of set Δ, we write d ∈ Δ. (Note the difference between the symbol ∈ for set membership, and the symbol ɛ sometimes used to designate the empty string.)
The empty set, written as ∅ or {}, has no members.
Boxes like this will contain various arcane comments that could be useful to some readers, but you'll probably want to ignore if you're learning these materials for the first time.
For a given set of things Δ, there is exactly one empty set of Δs, which contains no Δs. Where Δs and Γs are sets of things that are fundamentally different in certain ways, it’s less clear and more contentious whether the empty set of Δs and the empty set of Γs should be the same entity. But we will just ignore that issue.
Sets can have lots of members — even infinitely many — and they can contain sets which have lots of members. But on the standard (post-Russellian) picture, no set can have itself as a member. Nor can there be an infinite descending chain of sets, each of whom is a member of the next outermost set. That is, no sets like this:
{0, {1, {2, {3, ...}}}}
These claims aren’t indisputable, and alternative set theories have been developed which don’t respect them. But those kinds of controversies aren’t going to be our topic here. We’re just going to assume we’re working with well-behaved sets, we’re not going to worry about Russell’s paradox, and so on.
Some notable sets are:
ℕ, the set of natural numbers {0, 1, 2, ...} (a few authors exclude zero from what they call “the natural numbers,” but most include it)ℤ, the set of integers {..., -2, -1, 0, 1, 2, ...}ℤ₆, the set of integers modulo 6 {0, 1, 2, 3, 4, 5} (and similarly for other ℤn)ℝ, the set of real numbers (also called “the continuum”)𝟚, the set of of truth-values {false, true} (This notation is less common than the preceding ones. Sometimes this set is identified with ℤ₂.)
Sometimes mathematicians or logicians will specify a set by listing all its members:
{0, 16, 128}
Other times, they’ll specify the set using set-builder notation, which can look like this:
{x² | x ∈ ℕ}
{y | y ∈ ℕ and ∃x ∈ ℕ (y = x²)}
{y ∈ ℕ | ∃x ∈ ℕ (y = x²)}
All three of these expressions specify the same set. In the first two variants, the part to the right of the vertical bar | introduces some variables that range over a domain (in these examples, always ℕ) and may also be constrained to satisfy a guard condition; the part to the left of the vertical bar is then a term. The third variant can be understood as just a different style of writing the second.
Sometimes instead of a vertical bar, a colon is used: {x² : x ∈ ℕ}.
The language of these webpages, and most of your proofs, and most math textbooks and articles, will mix English and symbols in a way that may be precise, but nonetheless won’t count as a formal language like those of a logical system, with strictly regimented syntax. It’ll be an informal language, albeit one that contains lots of math notation.
Similarly, most of the proofs you’ll be reading and constructing won’t be formal proofs in a strictly regimented system like first-order logic. That is not to impugn them, or say they can’t be rigorous and convincing.
I draw attention to this now because the symbolism we use in our informal vs our formal languages can differ somewhat.
There are formal languages (and proof systems) for working with sets, but we’re not aiming to master them. Our references to sets will always be informal.
Although our informal language will use quantifiers like first-order logic does, authors will often specify what domain they’re drawing from when they use a quantifier. Thus I may write ∃x ∈ ℕ and not just ∃x. In the formal logical languages you first encountered in your studies, you’ll only have had the second, “unrestricted” quantifier. But some formal languages also introduce a “restricted” kind of quantifier too. The reasons for doing that are a topic for another discussion.
I’ll assume you’re familiar with basic set-theoretic operations and relations:
What does {2,3} ∈ {2,3,4} mean, and is it true?
What does {2,3} ⊆ {2,3,4} mean, and is it true? (See below.)
What does Γ ∩ Δ mean? What is {1,2,3} ∩ {2,3,4}?
What does Γ ∪ Δ mean? What is {1,2,3} ∪ {2,3,4}?
If Γ₀, Γ₁, ... Γn are sets, then another way to write Γ₀ ∪ Γ₁ ∪ ... ∪ Γn is 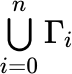 . Similarly for
. Similarly for 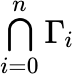 .
.
If Δ is a set of sets, then  is the union of all the members of
is the union of all the members of Δ. Or you could write 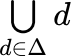 . Similarly for
. Similarly for 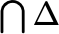 .
.
The “difference” between Γ and Δ — that is, the set of all members of Γ that aren’t also members of Δ — is sometimes written Γ ∖ Δ, but I prefer to write it just as Γ – Δ.
Sometimes people write  or
or  (or
(or Δ′, (Δ ∪ Γ)′). Here they are assuming some specific larger set Ω that Δ and Γ are subsets of, and these are just alternative ways of specifying Ω – Δ and Ω – (Δ ∪ Γ).
Δ is a subset of Ω when everything that’s a member of Δ is also a member of Ω. We write this relation as Δ ⊆ Ω. Ω may have additional members besides the things that are also in Δ. Or it may not. If it doesn’t, then Ω has exactly the same members as Δ. And as we understand sets, that means that they are exactly the same set. So among the sets that Δ is a subset of is itself.
If you want to say that Δ is a subset of and not identical to some other set Γ, then you say that Δ is a proper subset of Γ. Often that is written like this: Δ ⊂ Γ. But some authors use the symbol ⊂ the way we’ve explained ⊆. Sorry! If you want to avoid ambiguity, you could express the claim that Γ is a proper subset of, that is, is a subset of and is not equal to, Δ, like this: Δ ⊊ Γ. But I’ve tried doing that and people found it confusing or hard to read. (And some misinterpreted it as saying that Δ ⊈ Γ, that is, that Δ is not a subset of Γ.)
As we said, sets are the same when they have exactly the same members. For collections like multisets, which care about the multiplicity of their elements, then the collections will be the same when they have all the same elements to the same multiplicity. For collections like strings, which care about the order of their elements, then the collections will be the same when they have all the same elements in the same order. For collections with other sorts of structure, the rules will be analogous. There’s a general idea here, that the identity of a collection depends upon the identity of its elements and on any structure by which the collection organizes them, and on nothing more. You can’t have two collections with all the same elements organized (in the way that is inherent to that kind of collection) in the same way, yet those collections be numerically distinct. This general idea is called extensionality. (The root term “extensional” also has other meanings you may be familiar with. These meanings are conceptually related, but don’t expect that you could by unguided first principles derive specifically the one meaning from the other.)
When mathematicians or logicians work with a collection, they’ll almost always be understanding the collection to be one that’s extensional in the way I described. But in computer science contexts, this can’t be taken for granted. There it can be useful to introduce notions of structures that aren’t extensional, where we can have two numerically distinct but indiscernible collections, with the same elements organized in the same way. (For example, in Python, frozensets are extensional but what they call sets are not.) We’re not going to get into those contexts here. I’m just flagging that although the idea of an extensional collection is very natural and useful to work with, it’s not conceptually mandatory, and in some formal settings we can make good sense of, and it’s useful to work with, collections that aren’t extensional.
Here are some basic facts about unions, intersections, and subsets:
∅ ⊆ Α ⊆ Α (that means that ∅ ⊆ Α and Α ⊆ Α)∪ and ∩ are each commutative: this means, for example, that Α ∪ Β = Β ∪ Α∪ and ∩ are each associative: this means, for example, that Α ∪ (Β ∪ Γ) = (Α ∪ Β) ∪ ΓΑ ∩ Β ⊆ Α ⊆ Α ∪ ΒΑ ⊆ Β iff Α ∩ Β = Α iff Α ∪ Β = Β (iff means “if and only if” — you’ve encountered this by now in your philosophy studies, right?)Α ∩ Α = Α ∪ Α = Α ∪ ∅ = Α - ∅ = ΑΑ ∩ ∅ = Α - Α = ∅Α ∪ (Β ∩ Γ) = (Α ∪ Β) ∩ (Α ∪ Γ)Α ∩ (Β ∪ Γ) = (Α ∩ Β) ∪ (Α ∩ Γ)Α ∪ (Β - Α) = Α ∪ ΒΑ ∩ (Β - Α) = ∅Α ∪ (Α ∩ Β) = ΑΑ ∩ (Α ∪ Β) = ΑΒ - (Β - Α) = Β ∩ Α
The power set of a set Ω contains all and only the sets that are subsets of Ω. This includes Ω itself, and it includes the empty set ∅. That’s because all of the empty set’s members (all none of them) are also members of Ω. Sometimes the power set of Ω is written ℘(Ω), but I will write it as 𝟚Ω. (At some point, this notational choice may make sense. Until then, just take it as an arbitrary symbol.)
Thus the powerset of {1,2,3} is {∅, {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3}}.
When two sets have members in common, we say that the sets overlap. When the sets fail to have any members in common, we say that they’re disjoint. (The empty set is an edge case: should we define “disjointness” in a way to count it as disjoint from other sets, because their intersection is empty? Or should we count it as non-disjoint, since after all, it’s a subset of those other sets?) When two sets fail to be numerically identical, then — regardless of whether they overlap or are disjoint — we say that the sets are distinct.
In mereology, the formal theory meant to model our intuitive understanding of part-whole relations, they also use the term “overlapping.” But there instead of “disjoint,” they talk about things with no parts in common as being wholly “discrete.” Don’t confuse these vocabularies.
Partitions and Covers
A partition of a set is a division of the set into one or more (non-empty) “cells,” where everything from the original set gets to be in one of the cells, and none of the cells overlap. So, for example, here is one partition of the set {1,2,3}:
{1} {2,3}
The partition is itself understood to be a set — the set containing the two sets just listed. But for the moment I’ll just write out the elements of the partition separated with space, to make the intuitive idea more obvious. Another partition of the set {1,2,3} is:
{1,3} {2}
A cover is similar to a partition, except that now we’re allowed to have some overlap. It’s allowed (but not required) that some of the members of the original set get to be in multiple cells. So both of the above partitions of {1,2,3} also count as covers of that set. But so too does this:
{1,3} {2,3}
Covers come up sometimes in linguistics. We won’t need to work with them in this course.
Tuples (Ordered pairs, triples, …)
Sometimes we want to talk about several items taken from several sets. We do this using the notion of an ordered pair (or triple, or …) An ordered pair (a,b) has a “first” element a and a “second” element b. It’s permitted that these be the same object.
(Instead of (a,b), some authors will write ⟨a,b⟩.)
Two ordered pairs count as the same just in case they have the same first elements and the same second elements. The two elements might both be the same type of thing (they might both be members of the set of natural numbers ℕ, for example). Or they might be different types of things (maybe a is a number but b is a person). When Α and Β are two, not-necessarily-distinct, sets, we describe the set of all ordered pairs whose first element comes from Α and whose second element comes from Β as Α ⨯ Β. We can write this as:
Α ⨯ Β = {(a,b) | a ∈ Α and b ∈ Β}
This is called the Cartesian product of Α and Β. As I said, it’s permitted that Α and Β be the same set. We’ll see another notation for Α ⨯ Α below.
The ordered triple of Α, Β, and Γ we write as:
Α ⨯ Β ⨯ Γ = {(a,b,c) | a ∈ Α and b ∈ Β and c ∈ Γ}
In many mathematical and logical texts, you will see authors proposing reductions or equations between various of the notions we’re discussing.
For example, it’s common to see the ordered triple (a,b,c) defined as the pair (a,(b,c)) whose second element is itself a pair. But there might be settings where I need to differentiate between pairs that contain pairs, on the one hand, and triples on the other. In many computer science settings, for example, where we pay close attention to the types of things we’re working with, conflating these can be disastrous.
Another sort of reduction you will often encounter in math and logic texts is one that identifies ordered pairs with certain kinds of sets. There are different ways to do this. The most widespread proposal is that:
(a,b) =def {{a},{a,b}}
Other proposals reduce numbers to sets. (There are different ways to do this, too.)
It makes no mathematical difference for this course whether any of these equations or reductions are accepted. (Sometimes it can make a mathematical difference, if a proposed reduction is carried to other contexts, where it breaks.) The proposals may also matter in the philosophy of math, but for that very reason they are substantive and can be intelligibly debated. In any case, those are not our topics in this course.
So I’m going to downplay these reductions in our discussion. Even if we decided to accept some or all of them, I don’t think it’s right to offer them as introductory definitions of these notions.
I will myself tend to refrain from reductions like (a,b,c) = (a,(b,c)) that you see other authors going in for. The other authors may say that’s what a triple is, or how it’s defined. I’ll tend to say instead that the author is mathematically modelling or representing some notion (a notion we have some intuitive, somewhat pre-theoretical grasp on) in terms of (a,(b,c)). In some settings it’s worth keeping track of the difference. That’s why I’m flagging these things for you. I also think you’ll have better conceptual hygiene if you’re more aware of the choices to be made here. But for the material we’ll be focusing on, it won’t matter mathematically.
I talked about the “first” and “second” element of an ordered pair. But the suggestion of an “order” to these elements can mislead.
Really the important thing is just that we keep track of which element comes from which set, or which element comes from a single set playing the role of one side of the Cartesian product rather than the other. Instead of the “first” element and the “second” element, we could instead talk about the “west” element and the “east” element. And for ordered quadruples, about the “north,” “south,” “east” and “west” elements. If someone then took it in mind to ask whether the west element comes before or after the east element,
or whether the north element came in between them,
these questions wouldn’t have any established sense.
Similarly, if you take the ordered quadruple (a,b,c,d), we might call it “increasing” iff a ≤ b ≤ c ≤ d. But I could just as easily define another notion, call it “ascending,” which holds iff a ≤ d ≤ b ≤ c. There’s no sense in which one of these two notion is more intrinsically natural or less gruesome than the other.
With strings, on the other hand, the collection does have a more natural intrinsic ordering. It’s genuinely more natural to count the letter "b" as coming “between” the letters "a" and "c" in "abc" than it is to count "c" as coming “between” "a" and "b", because of way the string "abc" is inherently structured.
Sometimes ordered pairs, triples, and so on — the general class of things I will call n-tuples or just tuples — are referred to as “ordered sets.” Avoid this usage; it will be too confusing when we look at a different notion of ordered set, in a few classes.
The set Α ⨯ Α of pairs of Αs is sometimes written as A², and the set of triples Α ⨯ Α ⨯ Α written as Α³.
But then that raises the question whether:
Α ⨯ (Α ⨯ Α), that is, Α ⨯ Α², should = Α³ as well?
Those who identify (a₁,a₂,a₃) with (a₁,(a₂,a₃)) will say sure, because that’s just the same thing as Α ⨯ Α ⨯ Α. But then should it also be the case that:
(Α ⨯ Α) ⨯ Α = Α³
and so that ((a₁,a₂),a₃) always = (a₁,(a₂,a₃))? The Α³ notation papers over this issue. Nonetheless, I will sometimes go along with the notation because it’s very prevalant.
Don’t confuse Α² and 𝟚Α! The first is the set of all pairs both of whose elements come from Α. The second is the set of all subsets of Α (which as we said, some authors write as ℘(Α)).
Some More Vocabulary about Sets
Singletons are sets with just one member. For example, {"a"} is the singleton set containing the string "a" as its sole member. {{}} is the singleton set containing just the one member {}, that is, the empty set. Since another notation for {} is ∅, we could also write {{}} as {∅}.
If Γ is a subset of Δ (that is, Γ ⊆ Δ), then we can also say that Δ is a superset of Γ.
Pure sets are sets like {}, {{}}, {{},{{}}}, and so on, where no matter how deeply nested, none of the sets involved have any members that aren’t themselves sets.
We will discuss issues about the size or cardinality of sets later.
You may encounter talk of the rank of a set. The way this talk is used is this. At rank 0, we have all the sets whose members are only urelements. This includes at least the empty set. Potentially it could also include the set containing you and me, but standardly the rank-talk is used in theoretical settings where we assume everything being talked about is set-like — which you and I are not. So in that setting, there is only one set of rank 0, the empty set. A set belongs to rank k+1 when all of its members are (either urelements or) sets of rank ≤ k, and at least some of its members are from rank k.
You may encounter talk of the cumulative hierarchy of sets. This is another way of talking about rank — though sometimes the sets of rank k are counted as level k+1 of the cumulative hierarchy. On that way of talking, urelements belong to level 0, the empty set ∅ has rank 0 and belongs to level 1, the set {∅} has rank 1 and belongs to level 2, and so on.
You may encounter talk of classes. One can begin by thinking of these as collections like sets — and indeed every set is a class. However there are also thought to be some classes that are too “big” or “complex” to be sets. If there is some rank such that all the members of the class are ≤ that rank, then the class is allowed to be a set. If not, it’s not a set but a proper class. A distinguishing property of these is that sets can be members of other classes (sets or proper classes). However, proper classes can’t be members of anything.
The reason for making this distinction is that it enables us to avoid some paradoxes, like Russell’s set of all sets that aren’t members of themselves. In today’s mainstream set theory, every set fails to be a member of itself — but there is no set that contains them. (There is a class that contains them, but it’s not a set. It’s a proper class.) Neither is there any set that contains all the singleton sets (of arbitrary rank). In both cases, this is because there is no bound on the maximum rank of the things we’re talking about.
You might wonder: well, if there can be classes of such things but not sets, why don’t we just repeat Russell’s paradox at the level of classes? That is, what about the class of all classes that aren’t members of themselves? Well, among the classes that aren’t members of themselves are some proper classes, and these can’t be the members of anything. So there can be no class whose members are all classes that aren’t members of themselves, any more than there can be a set of all sets that aren’t members of themselves.
It may be helpful to think of all the class-talk as really just a covert way of talking about predicates. When we say that some classes are sets, we mean that some predicates define a set. When we say that other classes aren’t sets, we mean that other predicates don’t. In the latter cases, the classes can’t be members of anything because really there is no object that contains exactly the objects satisfying the predicate. Some of our talk about classes makes it look like they are a special kind of object, that somehow magically resists being a member of anything. But perhaps its best to think of that talk as superficial and misleading.
If you study set theory, you will learn more about this. We are not going to discuss it further here. I mention the notions of rank and class just to give you some orientation, so that if you encounter talk about these, you know where it should go in your mental map.