
We’re going to introduce a kind of formal system known as SRSs. That stands for string rewriting systems or string reduction systems, though you could also think of them as “Simplified Recursive uses of ’Secting” (short for Dissecting), since we’ll see a way to understand them as shorthand for what we can do with functions defined using dissect in a simplified/regimented way, that recursively re-invoke themselves.
These are also called Semi-Thue Systems, after the Norwegian methematician Axel Thue (pronounced approximately too, not as thew or too-eh). Pity his name didn’t begin with R.
Though an SRS will only use a simpler part of the full capacities of our dissect framework, it turns out that this simpler part is still “effectively complete,” that is, computationally equivalent to Turing Machines. Any formal algorithm we know how to express at all, can in principle also be expressed as an SRS. (That doesn’t mean it will be easy or straightforward to figure out how to do it.) In that sense, the SRS framework is no weaker than the full dissect framework, or the framework of Turing Machines, or any other formal model we have for expressing ways to effectively answer questions.
One difference between SRSs and the full dissect framework is that we’re no longer going to regard stinkiness as necessarily to be avoided. Remember what we’ve been counting as sources of stinkiness:
The simplified/regimented use we’ll make of the dissect framework won’t have space for possibility (a) to arise. Regarding the other possibilities, we’re no longer going to think of ourselves as defining a (partial) function from an input string to a single output string. Instead, we’ll think of ourselves as defining a relation between the input string and zero or more output strings. Another way to put it is that our definition captures a set of output strings (all the ones that the input string is related to). When the definition can deliver multiple results for some input, that means the input is related to all of them. When the definition recurses forever for some input (on all ways of matching it), that means the input isn’t related to any output strings. When the definition recurses forever on some ways of matching an input, but delivers results on other ways of matching it, that means the input string is related only to the results that ever get delivered.
Let’s look at some examples. Here is an SRS that translates input strings of one or more xs to output strings made of 1s and 0s, where the output is the binary representation of the number of xs in the input string.
Unary to Binary
1x ⟶ x0
0x ⟶ 1
^x ⟶ 1
The way to interpret these rules is that whenever an input string contains the left-hand side (lhs) of any of the rules as a substring, that may be replaced with the right-hand side (rhs). There is no precedence or order in which the rules have to be tried, and if a lhs occurs multiple times in an input string, there is no precedence or order to which occurrence should be replaced. All ways of proceeding are allowed. We count ourselves as reaching an output string when we have a result to which no rules anymore apply.
The ^x on the lhs of the final rule of this SRS means that the pattern is an x, but it has to occur at the start of the matched string.
Let’s see this SRS in action. We’ll start with the input string "xxxxx". Underlining will represent which substring is going to be replaced, and the bold text on the next line will be the string that replaced it. When multiple rules match, or one rule matches different substrings, we’ll choose one arbitrarily, and display the ones we’re not pursuing as a parenthetical aside. In this SRS, it happens that for any input string of one or more xs, all the different ways of proceeding reach the same final result.
xxxxx 1xxxx x0xxx (or x0xxx) 10xxx 11xx 1x0x (or 1x0x) 1x1 x01 101
Here’s another example. This time, our SRS translates input strings of binary digits into an output string of zero or more xs that represent the same number.
Binary to Unary
x0 ⟶ 0xx
1 ⟶ 0x
^0 ⟶ ɛ
Let’s see this SRS in action, starting with the input string "101".
101 0x01 (or 0x01) x01 0xx1 (or 0xx1) 0xx0x (or 0xx0x) xx0x x0xxx 0xxxxx xxxxx
LIke the previous SRS, this one is also non-deterministic: that is, for some input arguments there are multiple rules that can be applied next. But as before, here also you get the same result no matter which way you proceed. These two SRSs happen to be non-stinky.
Here are some examples of stinky SRSs:
Stinky1
x ⟶ xx
Stinky2
x ⟶ x
Neither of those SRSs will deliver any result for input strings containing "x". In other words, the relation they define is one those input strings don’t stand in to any output string.
Here is another example:
Stinky3
x ⟶ 0
x ⟶ 1
This relates the input string "x" to all of the output strings in {"0", "1"}, and the input string "xx" to all of the output strings in {"00", "01", "10", "11"}.
Here is an example, that, though it is stinky, still manages to be winky:
Stinky4
x ⟶ x
x ⟶ 1
This relates the input string "x" to the single output string "1", the input string "xx" to the single output string "11", and so on. It counts as stinky because there are some paths that recurse forever, but when there are, there are also paths that deliver a result; moreover, there is only ever one result that gets delivered.
Recall the first SRS we gave above:
Unary to Binary
1x ⟶ x0
0x ⟶ 1
^x ⟶ 1
Here is how to understand that in terms of the dissect framework:
unary2bin(γ) = dissect γ {
λ α ⁀ "1x" ⁀ β ! unary2bin(α ⁀ "x0" ⁀ β);
λ α ⁀ "0x" ⁀ β ! unary2bin(α ⁀ "1" ⁀ β);
λ "x" ⁀ β ! unary2bin( "1" ⁀ β);
λ β . β
}Notice that there are no guard conditions in this dissect construction. Nor are there any undefined results, or any results that don’t match a specific form — except for the final default clause, which just returns the input string unaltered. All the other clauses have the same precedence, and re-invoke the function recursively with the result of replacing the lhs substring with its paired rhs. Also, the only pattern variables in this dissect construction are the α prefix and β suffix that are left implicit in the SRS formalism.
Sometimes we work with SRSs packaged in a form called a grammar. When we do this, we understand the SRS to have a little extra structure.
Any SRS will have an alphabet of symbols from which its rules are built. In our examples above, the alphabet was some or all of {"x", "0", "1"}. When we talk about an SRS as a grammar, we understand its alphabet to be divided into two (non-empty, non-overlapping) parts, one called the terminal symbols and the other called the non-terminals or category symbols.
When we talk about an SRS as a grammar, we also understand it to be operating on only one input string (and any results derived while doing that). This input string consists of a single occurrence of one of its category symbols, which is called the starting symbol.
We are only interested in output strings that are made up entirely of terminal symbols. We can prevent other output strings from even being delivered (at the cost of mild stinkiness), by adding rules that match any remaining category symbols, until they’ve all been replaced by other rules with terminals.
The lhs of every rule will contain at least one category symbol.
Grammars of this sort are called unrestricted grammars, or (in linguistics circles) type-0 or phrase-structure grammars.
As these grammars are often presented, Constraint 4 is relaxed to require only that a rule’s lhs is never the empty string. But the Constraint 4 we’re imposing here doesn’t introduce any substantial restriction. It just requires the rules to be formulated with a particular shape. It also makes the continuity clearer to the context-free grammars we’ll discuss below, that are substantially more restricted.
The clauses of a grammar are called production rules or rewrite rules or phrase-structure rules.
We talk of grammars as generating all the output strings made only of terminals that are derivable (after finitely many rewriting steps) from their starting symbols. That set of strings is called the language generated by the grammar. One and the same language may be generated by grammars with different rules (see for example the subtraction language we discuss below). We talk of Turing Machines and other formal automata instead as “recognizing” a set of strings (language). That’s another way to say that the automaton effectively yesses which strings belong to that set.
Here’s an example of a grammar. Its terminal symbols will be the English words {"frogs", "that", "swim", "chase"}. Its category symbols will be {SENTENCE, NP, VP}. The start symbol is SENTENCE.
SENTENCE ⟶ NP VP
NP ⟶ frogs
NP ⟶ frogs that VP
NP ⟶ frogs that NP chase
VP ⟶ swim
VP ⟶ chase NP
Remember, the top-to-bottom order of the rules has no significance.
On the right-hand sides, concatenation is implicit. So the first rule really means SENTENCE ⟶ NP ⁀ VP; and the third rule really means NP ⟶ "frogs" ⁀ "that" ⁀ VP.
Also, it’s no problem for the same lhs to appear on different rules. That just makes the grammar non-deterministic, so it may end up delivering more than one result.
Here are some examples of how the starting symbol can be rewritten into different strings, eventually resulting in a string of terminals (the leaves of each tree):
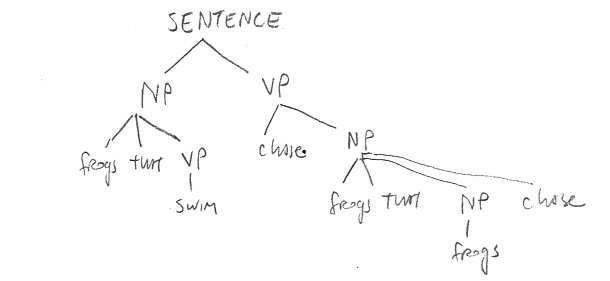
A grammar only delivers (zero or more) output strings of terminals, like "frogs chase frogs", not these tree structures. What the tree structures represent are which rules were applied to each part of the input string (and strings derived from it) to eventually reach some output string. Such trees are called derivation or parse trees. The tree does not encode every fact about the order in which rules were applied. For example, in the second tree SENTENCE is rewritten to NP VP. The tree does not tell us whether we next apply the rule
NP ⟶ frogs, or whether we first apply the rule
VP ⟶ chase NP.
In the third tree, the rewriting may proceed in such an order that at one point we have NP chase NP. Notice that the two occurrences of the NP category can be rewritten in different ways. The first will end up as "frogs that swim", and the second as "frogs that frogs chase".
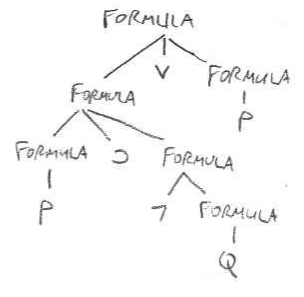
Here is an example of a parse tree for the grammar of a logical language. This is how the string ((P ⊃ ¬Q) ∨ P) may be derived from the category FORMULA.
Sometimes a grammar can deliver the same output string by different parse trees. For example, here are two derivations for a hypothetical grammar for English. (We don’t spell out the grammar.)
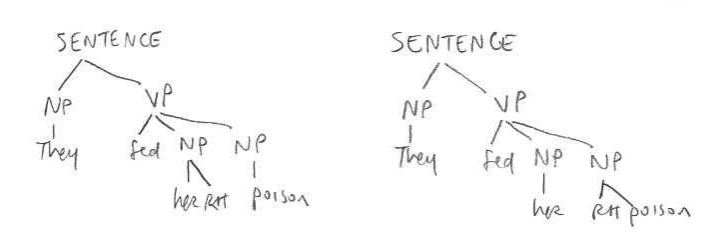
When this can happen, the grammar is called ambiguous. (This only concerns “structural” ambiguity, not the kind of ambiguous meaning that some particular words have. For example, in Homework 6 Problem 74, the word "fish" is sometimes used as in its verb-form meaning, and sometimes as a noun.)
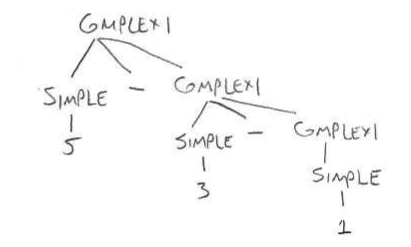
In class we discussed two grammars for representing subtraction. Here’s one of them:
COMPLEX1 ⟶ SIMPLE – COMPLEX1
COMPLEX1 ⟶ SIMPLE
SIMPLE ⟶ 5
SIMPLE ⟶ 3
SIMPLE ⟶ 1
This can generate the string 5 – 3 – 1, as follows:
Here’s the other one:
COMPLEX2 ⟶ COMPLEX2 – SIMPLE
COMPLEX2 ⟶ SIMPLE
SIMPLE ⟶ 5
SIMPLE ⟶ 3
SIMPLE ⟶ 1
This can also generate the string 5 – 3 – 1, as follows:
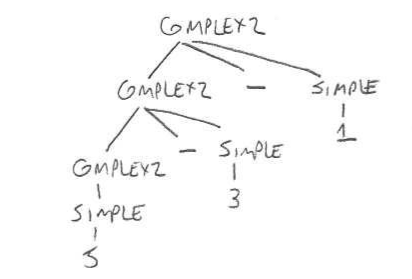
As we discussed in class, the second of these grammars seems to better fit our conventional understanding of the string 5 – 3 – 1, as the second grammar says that 5 – 3 is one component, from which 1 is then subtracted. And that’s how we in fact understand the string 5 – 3 – 1. The first grammar says that 3 – 1 is one component, which is then subtracted from 5. We could have understood 5 – 3 – 1 that way, but in fact we don’t.
Note that the example of these two grammars doesn’t exhibit any ambiguity. They are two competing grammars, that each generate the string 5 – 3 – 1 in an unambiguous way. They just disagree about what way it happens.
When we were explaining unrestrictred grammars, we said that the only constraint on the left-hand side of a rule is that at least one category symbol occurs. There may be many category symbols, even many occurrences of the same category symbol, and they may be mixed with terminal symbols. But in the examples we’ve been discussing, all our left-hand sides consisted of a single category symbol. Grammars with this restricted form are known as context-free grammars or CFGs. Why “context-free”? Because they say that the category symbol may always be rewritten to such-and-such a rhs no matter what other symbols come before or after it.
CFGs are computational less powerful than unrestricted grammars. There are some sets of strings (what we call “formal languages”) that can be generated by an unrestricted grammar but not by any context-free grammar. However, CFGs are easier to work with and for many purposes they suffice.
When we’re writing a CFG, we often use certain shorthands. For instance, we’ll use vertical bars to collapse several rules into a single line, so that the grammar for COMPLEX2 above can be written more compactly as:
COMPLEX2 ⟶ COMPLEX2 – SIMPLE | SIMPLE
SIMPLE ⟶ 5 | 3 | 1
Also, the kind of pattern we see in the rules for category COMPLEX2 is very common, and we can write that more compactly like this:
COMPLEX2 ⟶ (SIMPLE –)* SIMPLE
The (...)* means zero or more repetitions of .... (Notice that the – is being used as a terminal symbol, whereas the * is part of our grammatical notation that represents repetition. If we also wanted to include * as a terminal symbol, we’d have to make sure the different uses are clearly distiguishable.)
These two grammars would also be equivalent:
START ⟶ START 1 0 | ε
–––––––––––––––––––––––––
START ⟶ (1 0)*
This shorthand (...)* is sometimes instead written as {...}, with curly brackets and no *.
We also use (...)+ to mean one or more repetitions of .... Thus these two grammars would be equivalent:
START ⟶ START 1 0 | 1 0
–––––––––––––––––––––––––
START ⟶ (1 0)+
That could also be written as (1 0)* 1 0.
We also use (...)? to mean zero or one occurrences of .... Thus these two grammars would be equivalent:
START ⟶ 1 0 | ε
–––––––––––––––––––––––––
START ⟶ (1 0)?
This shorthand (...)? is sometimes instead written as [...], with square brackets and no ?.
Here’s another example:
START ⟶ a START | FINISH
FINISH ⟶ b FINISH | ε
That grammar could also be written as:
START ⟶ a* | b*
and generates all strings consisting of zero or more "a"s followed by zero or more "b"s.
Here’s another example:
START ⟶ a START b | ε
This string generates all strings consisting of zero or more "a"s followed by the same number of "b"s.
We can also give a CFG that generates all strings consisting of the same number of "a"s and "b"s, but where the "a"s aren’t necessarily all to the left of the "b"s. This grammar is more complex:
SAME ⟶ a SAME b SAME | b SAME a SAME | ε
Here’s another example:
START ⟶ a START a | b START b | a | b
This grammar generates all “odd palindromes” made of "a"s and "b"s, that is, strings consisting of some substring α, followed by an "a" or a "b", followed by reverse(α).
A small modification (can you figure it out?) gives us a grammar that generates all “even” palindromes, that is, strings of the form α ⁀ reverse(α).
(It is not possible to give a context-free grammar that generates all strings of the form α ⁀ α, that is, where the second copy of α is unreversed. Doing that needs the resources of less-restricted grammars.)
Here is a more complex CFG, for the programming language Lua. It uses the {...} and [...] notation instead of (...)* and (...)?. Notice that they also use ::= where we’re using ⟶ . Different presentations separate the lhs and rhs of a rule in various ways. The category symbols here are chunk, block, stat (for “statement”), and so on. (Also Name, Number, and String, whose rules aren’t presented here.) The terminal symbols appear as boldface strings like break or as quoted punctuation like ';' or '='.

That’s the grammar for Lua version 5.2. It’s not the latest version of the Lus programming language, but the grammar becomes somewhat more complex in later versions.
Here is a more complex CFG for the Python programming language, version 3.8. In later versions, Python shifted to writing its grammars in forms that are no longer CFGs.
But the grammars/syntax of formal languages are very often formulated as CFGs.
There is some controversy about the extent to which the syntax of natural languages can be captured by CFGs. But it’s agreed that most constructions in most languages are representable as CFGs. Some theorists think that many languages like English have syntax that can be entirely captured by CFGs; others disagree. But here is some discussion, and links to more.
Some questions about CFGs are decidable:
α, can that CFG generate that string?Many questions are not decidable. (They may be decidable for particular CFGs, but there won’t be an effective way to decide the question for any CFG.)